


数据分析
源码页面:https://halo.suzakudry.top/yuan-ma-dang-an
源码github: https://github.com/FCYXSZY/-
Pixiv插画作品元素流行趋势分析·1
本项目主要目的为爬取Pixiv的的图片相关信息,进行数据分析。
(例如点赞、收藏、浏览量等)
同时添加了自定义 评分 = 0.3\*点赞量+0.5\*收藏量+0.2\*浏览量
项目地址:
项目框架
pixiv-
├── flask2
│ ├── app.py web框架
│ ├── DAO.py 数据库交互层
│ ├── reptile.py 爬虫
│ ├── dataSql.DB 数据库存储爬取的信息
│ ├── static 存储html静态资源
│ └── templates 存储html模板
├── config 配置文件COOkie和UA模拟浏览器登录,和数据库地址
├── output 存储爬取的图片
├── README.md 项目说明
└── requirements.txt 项目依赖,自动创建虚拟环境项目使用到的工具
SQLite 轻量内嵌式数据库。存储数据也可以用Excel
lxml 解析html网页(解析request的response.text),c语言实现速度较快。流程:->解析:lxml.etree->提取:html.xpath
pandas 数据
requests 网络请求(requests简明介绍)
selenium 模拟浏览器
pyecharts 数据可视化绘图 (数据可视化也可以用matplotlib,但由于我是部署到网页web端上了,而,pyecharts 生成的图表是 HTML + JavaScript 格式,可以直接嵌入网页中,且具有交互性。而matplotlib生成的一般是图片格式的静态表格效果不太好。)
flask web框架(简单应用:halo.suzakudry.top/archives/flaskjian-dan-shi-yong)
Jinja2 模板引擎用于生成网页(不怎么会用)
tqdm 过程可视化(拒绝枯燥的等待时间)
运行环境
python3.9
windows11
答辩内容
Part1.数据收集
- 爬取内容:
爬取内容主要包括Pixiv网站上的艺术作品信息,包括作品的标题、作者、图片链接、浏览量、点赞数、收藏数以及标签等。
即图中数据库类型的内容。

- 爬取方法:
爬虫相关:
使用selenium(通过web_driver自动化web测试)爬取。
后改用selenium+requests的方式,先用自动化爬取要下载的具有反爬虫规则的图片链接,并在此阶段收集网站图片的信息:标签作者浏览量等
后通过requests下载二进制数据的图片。
实现:
先通过沿着插画排行榜页面爬取每个作品的id信息。
通过requests 得到网页的HTML 页面源代码(字符串格式),
在通过lxml库中的模块etree的etree.HTML(context)解析成一个可供操作的树形结构,
然后可以通过Xpath、ID、类名、CSS选择器等方法提取信息。(Xpath基本语法)
提取id后,拼接成每个作品的链接(f'https://www.pixiv.net/artworks/{作品id}')。def get_NewPage(url): if url == "": url = "https://www.pixiv.net/ranking.php?mode=daily&content=illust" print(url) context = requests.get(url = url,headers=headers,proxies=proxies).text html = etree.HTML(context) print('finished get') nowtime = html.xpath('//*[@id="wrapper"]/div[1]/div/div[2]/div/nav[2]/ul/li[2]/a/text()')[0] # 获取当前排名的日期----nowtime print(nowtime.encode("utf-8").decode("utf-8")) o = html.xpath('/html/body/div[3]/div[1]/div/div[3]/div[1]/section/div[2]/a[1]/@href') o = [up_url+x for x in o if "user" not in x] # 各个作品的网页 return o,nowtime,html
然后应该是通过自动化进入每个作品的页面爬取信息,
但发现原始的图片链接具有反爬虫规则,
不登录,或者不点击缩略图进入大图模式,连链接都获取不到……
所以需要配置cookie模拟用户登录,如下:# 获取Cookie并加载到Selenium中 def getCookie(driver): driver.get("https://www.pixiv.net/") time.sleep(60) print(driver.get_cookies()) with open('cookies.txt', 'w') as f: f.write(json.dumps(driver.get_cookies())) def login(driver): driver.get("https://www.pixiv.net/") with open('cookies.txt', 'r') as f: cookies_list = json.load(f) for cookie in cookies_list: # 检查并转换Cookie中的expiry字段 if isinstance(cookie.get('expiry'), float): cookie['expiry'] = int(cookie['expiry']) driver.add_cookie(cookie) driver.refresh()
登录完成。
现在通过自动化进入每个作品的页面爬取信息,使用selenium的find_element方法,通过Xpath、ID、类名、CSS选择器等获取数据。(此处获取到作品的标题、作者、图片链接、浏览量、点赞数、收藏数以及标签等)def getDataFromWeb(url, nowTime): global browser, download_num browser.get(url) taget = [a.text for a in browser.find_elements(By.CLASS_NAME,'gtm-new-work-tag-event-click')] temp = [b.text for b in [a.find_element(By.TAG_NAME,'dd') for a in browser.find_element(By.CLASS_NAME,'dpDffd').find_elements(By.TAG_NAME,'li')]] writer = browser.find_element(By.CLASS_NAME,'fATptn').find_element(By.TAG_NAME,'div').text imgurl = '' if download_num > 0: try: image_element = browser.find_element(By.CSS_SELECTOR, "img.sc-1qpw8k9-1") parent_a_element = image_element.find_element(By.XPATH, "..") image_url = parent_a_element.get_attribute("href") #image_url = image_element.get_attribute("href") # url_match=ret_match(image_url) # original_image_url = extract_and_build_pixiv_url(url_match) # imgurl = url_match original_image_url= [image_url] imgurl = image_url print(f"Image URL: {imgurl}") if(download_num==1): pass else: download_list.extend(original_image_url) download_num -= 1 except Exception as e: print('不许看哦') pass #print(f"Error while downloading image: {e}") return [nowTime, writer, temp[0], temp[1], temp[2], taget, imgurl]
获取的数据先存储到list里,def thread_getData(url_list,nowTime): for url in tqdm(url_list, desc="获取数据进度", ncols=100, unit="项"): # 使用 tqdm 包装 url_list print('--'+url) data_list.append(getDataFromWeb(url,nowTime))
最后通过df的构造函数转为df数据,打上标签通过DAO(数据交互层),使用df的to_sql方法,将数据导入数据库,实现数据可持久化。
(坑点:国外网站数字会以这种形式1,000,000,所以先去掉顿号",",然后再转成数字类型)
data = pd.DataFrame(data_list)
data.columns = ['日期', '作者', '点赞', '收藏', '浏览', '类型', '图片url']
data['点赞'] = data['点赞'].str.replace(',', '')
data[['点赞']] = data[['点赞']].astype('int')
data['收藏'] = data['收藏'].str.replace(',', '')
data[['收藏']] = data[['收藏']].astype('int')
data['浏览'] = data['浏览'].str.replace(',', '')
data[['浏览']] = data[['浏览']].astype('int')
data['日期'] = data['日期'].astype('string')
data['作者'] = data['作者'].astype('string')
data['类型'] = data['类型'].astype('string')
data['评分'] = round(data.点赞 * 0.3 + data.收藏 * 0.5 + data.浏览 * 0.2,2)
data['图片url'] = data['图片url'].astype('string')
DAO.insert(data)
图片的爬取
上述使用了selenium爬取作品的一系列特征信息,但并没有实现爬取图片。(因为并不会)
以下再次使用requests实现图片下载。
首先,因为是国外网站,要配置代理。使用selenium时设置代理比较简单browser_options.add_argument("--proxy-server=" + proxy)
但是在使用request是发现直接使用这样的代码配置后传入,会出现proxyERROR
错误代码:
proxy = {
"http": "http://127.0.0.1:7890",
"https": "https://127.0.0.1:7890"
"socks":'socks5://127.0.0.1:7890'
}
………………
requests.get(url, headers=headers, proxies=proxy)
报错:proxyERRORhttp 和 https 的代理协议(详解http和https)
即使目标网址使用 HTTPS 协议,是代理服务器和目标服务器的传输,而客户端与代理服务器仍然通常使用 HTTP 协议 作为传输方式。因此,代理 URL 应写成 http:// 而不是 https://。
#正确配置
proxies = {
"http": "http://127.0.0.1:7890",
"https": "http://127.0.0.1:7890",
"socks":'socks5://127.0.0.1:7890'
}之后是设置header,用来伪装浏览器请求。
headers = {
"Cookie": Cookie ,
"User-Agent": 模拟浏览器标识
}准备到这。下载原图还是下不下来了,因为pixiv还有一重防盗链保护"referer" ,这里不细讲了,感兴趣可以去我博客看。
链接:referer防盗链
总之突破了反爬机制后。直接通过以下代码保存到本地即可 。
#直接 response = requests.get ()然后.content()获取图片二进制数据(或者.iter_content()分块获取)
response = requests.get(url, headers=headers, proxies=proxy_config.proxy)
sleep(0.5)
#(细节,请求完time.sleep(几秒)一下,不然由于请求频繁,服务器会强制关闭连接。 ConnectionResetError 别问我怎么知道的)
if response.status_code == 200:
#分快下载优点
#支持断点续传(已经写入的数据仍然安全地存储在文件中)直接调用write当出现网络波动会直接下载失败。
#降低内存占用
#wb 只写方式打开或新建一个二进制文件,只允许写数据。
with open(save_path, 'wb') as f:
for chunk in response.iter_content(1024): # 分块写入文件
f.write(chunk)常见的简单反爬突破方法还有 通过User-Agent来控制访问 IP代理池 模拟浏览器行为 等等
(更多细节见github,或我的博客)
2, 数据处理
首先确认下已有的信息:包括作品的原图,标题、作者、图片链接、浏览量、点赞数、收藏数以及标签等。
通过数据处理库,进行数据分析和解读,提取有价值的信息。
先明确该清洗掉哪些信息,标签,哪些是无用的?
此处定义有用信息。
有用信息的判断标准:
对分析目标有帮助:
标签“日期”用于流量和评分的时间变化趋势。
标签“自定义评分”是分析作家和作品质量的关键指标。
标签“收藏”用于评估作品热度,筛选出受欢迎的作品。
对模型训练或可视化有价值:
标签“类型”代表作品内容的主题,可以帮助生成热点标签词云。
最后数据分析大师chatgpt决定需要清洗处理的数据为:
重复数据
空值并填充空值
无用标签
异常值
。。。。。。。。。。。。
数据预处理过程
def pre():
global data
sql = "select * from test"
data = DAO.select_data(sql)
data = data.drop_duplicates()
# 删除空值或填充空值
data = data.dropna(subset=['日期', '评分']) # 删除“日期”和“评分”为空的行
data['评分'] = data['评分'].fillna(data['评分'].mean()) # 填充评分的均值
# 清理无用标签
data['类型'] = data['类型'].str.replace(r'users入り', '', regex=True) # 去掉无意义的标签
data['类型'] = data['类型'].str.replace(r'[^\w\s,]', '', regex=True).str.strip() # 去掉标点和多余空格
# 去除异常值(以评分为例)
q1 = data['评分'].quantile(0.25)
q3 = data['评分'].quantile(0.75)
iqr = q3 - q1
data = data[~((data['评分'] < (q1 - 1.5 * iqr)) | (data['评分'] > (q3 + 1.5 * iqr)))] # 去掉评分异常值
Part3, 数据分析与可视化
分析数据的特征
数据的维度包括:
作品的浏览量:评估作品的受关注程度。
作品的点赞:反映作品的喜爱程度。
作品的收藏:体现作品的长期价值和用户粘性。
作品的标签 :提取作品的主题或风格特征。
通过多维度的信息,得出作品的综合评分。
通过分配不同的权重得到 综合评分 = 0.3\*点赞量+0.5\*收藏量+0.2\*浏览量
可视化效果:
图片中的艺术作品信息可视化展示。通过图表、图形等方式展示艺术作品的数据信息,让读者更直观地了解作品的受欢迎程度及流行趋势。
折线图:展示数据变化趋势。
柱状图:对比不同作品的表现数据。
时间轴图:分析流行趋势的时间分布。
词云图:呈现作品的热门标签或关键词。
j可视化图标都是通过pyecharts生成,代码大差不差,展示其中较复杂的词云生成:
def hotWord_base()->WordCloud:
# 热点标签生成
label_value = {}
for i in range(len(data)):
if data['收藏'][i] >= 1000:
temp = data['类型'][i].split(',')
temp = [var.replace('[', '').replace(']', '').replace("'", '').strip() for var in temp]
temp = [var for var in temp if not var.endswith("users入り")]
for v in temp:
if v not in label_value.keys():
label_value[v] = 0
label_value[v] += data['评分'][i]
label_value = label_value.items()
# 创建词云图
c = (
WordCloud()
.add(series_name="热点标签", data_pair=label_value, word_size_range=[20, 80]) # 调整字体大小范围
.set_global_opts(
title_opts=opts.TitleOpts(
title="热点标签", title_textstyle_opts=opts.TextStyleOpts(font_size=23)
),
tooltip_opts=opts.TooltipOpts(is_show=True),
)
.set_series_opts(
#设置为菱形
shape="star", # 设置为圆形
word_gap=5, # 设置词与词之间的间距
rotation_range=[-90, 90] # 允许词云旋转
)
)
# 调整图表的宽度和高度(可选,视需要)
c.width = "100%" # 设置为100%的宽度,适应屏幕
c.height = "1050px" # 设置词云图的高度
return c全部实现方法:
用 Flask 框架构建的 Web 应用,使用Jinja2 环境来加载模板并生成最终的 HTML 内容。
主要通过 pyecharts 实现可视化数据。
代码结构中还包含了数据库操作、静态文件的管理,以及通过 waitress 部署服务器。
最后通过docker 将微服务部署到服务器上,提供在线访问。
最后的最后通过通过Nginx将ip地址反向代理到域名上,且隐藏真实ip
不再一一介绍,最后的效果为——
且通过热点标签分析,得到以下结论:
pixiv插画网站虽远在日本,但也远受国产游戏米哈游的影响,出现大量米哈游旗下作品(原神等)的同人作品。
…………………………等
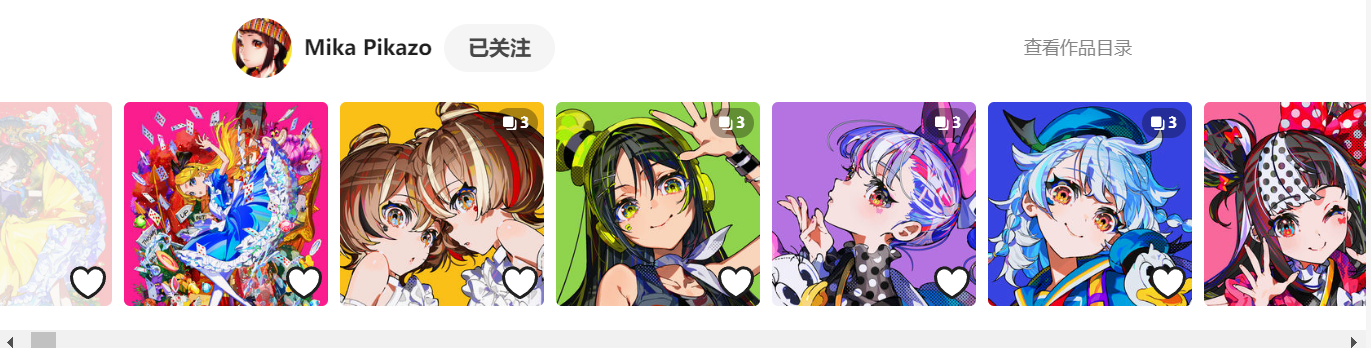
同时,通过数据分析,发掘了具有潜力新人画师Mika pikazo,其风格如下。
part4.数据与应用
一,通过收集的图片,训练sd类图片生成式模型,投入实际生产绘图。
二,通过经过筛选的图片,训练ai模型,实现自动筛选符合用户预期的图片。
三,通过已有的标签热度,为作者和用户提供预测作品的流行趋势。
未完待续(并不会机器学习。)
----------to be continued----------
总结(ai生成人工润色)
Pixiv插画作品的流行趋势分析总结
本项目的目标是通过爬取Pixiv网站排行榜的插画作品信息,分析流行趋势,尽可能地描述插画作品在网站上的热度和大众兴趣。
一、数据采集
1. 爬取内容
爬取目标:
作品的标题
作者名称
图片链接
浏览量
点赞数
收藏数
标签
工具实现:
Selenium + Requests:模拟浏览器登录。
**Referer模拟:**实现正常的HTTP请求,回避403错误。
**网络代理配置:**解决国外网站加载慢问题。
**文件下载:**分块下载实现、支持断点续传。
最终爬取结果:
插画数据存储在SQLite数据库中,进行处理和分析。
图片存储在output里
2. 触发问题及解决方案
**Cookie和Referer模拟:**正确的Referer和Cookie是破解Pixiv反爬机制的关键。
**常见问题:**403错误,反爬拦截。
解决方案:
使用正则表达式获取插画ID,并拼接Referer链接。
配置正确的HTTP和HTTPS代理。
模拟浏览器:
通过Selenium实现自动登录与数据爬取,有效解决登录验证与数据加载问题。
二、数据处理
数据清洗:
删除重复数据。
填充空值,确保完整性。
清理无用标签。
移除并处理异常值。
关键数据:
**日期标签:**分析作品流量和评分随时间的变化趋势。
**评分标签:**衡量作者作品质量的重要指标。
**收藏标签:**用于评估作品热度和用户喜爱程度。
**类型标签:**用于生成热点词云,识别流行主题。
工具:
使用Pandas进行数据清洗和转换,为分析提供支撑。
三、数据分析
基于以下维度:
作品浏览量:
监测作品在用户中的曝光度。
分析浏览量的时间分布,识别流行时段。
点赞数与收藏数:
作品的点赞数和收藏数是流行程度的重要指标。
比较不同标签和类型的作品受欢迎程度。
标签热度分析:
通过标签词云展示流行的关键词和主题。
识别长期和短期流行标签。
时间趋势:
分析作品流行趋势的时间变化。
识别哪些作品类型或标签在特定时间段更受欢迎。
四、预测与应用
通过收集和分析的数据,可以实现以下应用:
评分预测模型:
使用机器学习模型(如线性回归、决策树等)基于标签、浏览量、点赞数等特征预测作品评分。
帮助创作者了解哪些元素更容易提升作品的受欢迎程度。
流行趋势预测:
通过时间序列分析,预测特定标签或作品类型的未来流行趋势。
提供数据支持,帮助用户把握创作方向。
作品自动筛选:
基于用户偏好标签,自动筛选符合预期的作品。
提供个性化推荐,提升用户体验。
AI生成画风模拟:
利用爬取的插画图片数据,训练生成式AI模型(如Stable Diffusion)。
模拟画师风格,自动生成符合特定风格的插画作品。
五、总结与展望
本项目通过Pixiv数据的爬取、清洗与分析,实现了对插画作品流行趋势的深入挖掘。未来,通过引入评分预测模型和AI生成技术,可以进一步实现作品流行趋势的预测和个性化推荐,为创作者和用户提供更加智能化的服务。
评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果